
机器人时代的到来:黄仁勋揭秘AI革命与AI训练数据采集的未来
探索机器人时代的到来,从黄仁勋在Computex 2024上的演讲揭示AI革命和数据采集的重要性。了解如何利用Pangolin Scrape API提升数据采集效率,为智能机器人训练提供支持,推动AI技术的未来发展。
机器人时代的到来:黄仁勋揭秘AI革命与AI训练数据采集的未来 Read More »
探索机器人时代的到来,从黄仁勋在Computex 2024上的演讲揭示AI革命和数据采集的重要性。了解如何利用Pangolin Scrape API提升数据采集效率,为智能机器人训练提供支持,推动AI技术的未来发展。
机器人时代的到来:黄仁勋揭秘AI革命与AI训练数据采集的未来 Read More »

亚马逊作为全球最大的电商平台之一,拥有庞大的数据资源。对于卖家、市场分析师和研究人员而言,如何高效地获取亚马逊上的数据成为了一大难题。本文将深入探讨亚马逊数据采集的现状和面临的困难,介绍主流的解决方案及其弊端,重点介绍Pangolin Scrape API和Pangolin采集器的特点、相同点和区别,从多个角度进行分析,以帮助读者在选择亚马逊数据采集工具时做出明智的决策。
亚马逊数据采集工具:选择Scrape API还是Pangolin采集器? Read More »

通过聚焦于亚马逊数据采集的实际应用、挑战和解决方案,本文为希望利用亚马逊采集 API 的企业提供了全面指南,如何实现实时一键采集亚马逊站点所有数据,特别强调了 Pangolin Scrape API 的创新功能。轻松嵌入现有数据平台。
亚马逊采集 API:一键实时采集亚马逊全站数据 Read More »

在当今信息爆炸的时代,数据成为了企业决策的重要依据。然而,海量的数据如何有效地获取和利用,成为了企业面临的重大挑战。自动化数据采集器应运而生,成为解决这一问题的利器。本文将深入探讨自动化数据采集器的重要性、发展背景、应用场景、技术挑战,以及特别介绍一种新兴的产品——Pangolin采集器,分析其市场前景与挑战。
Pangolin采集器:自动化数据采集器的革新与应用 Read More »
探索最新的网页数据抓取技术及其优势与不足。了解如何利用”(Pangolin Scrape API)穿山甲数据抓取API”简化数据收集流程,提升效率。本文深入分析了网络爬虫技术的发展,提供了实用的SEO策略和解决方案。
最新Web数据爬取技术及其优劣势分析 Read More »

人工智能(AI)已经成为现代科技发展的核心力量,其在各个领域的应用正在不断扩展,从自动驾驶到医疗诊断,从自然语言处理到图像识别,无一不依赖于高质量的训练数据。训练数据的质量直接决定了AI模型的性能和准确性。因此,如何高效地采集和处理训练数据成为了AI研究和应用中的关键问题。本文将详细探讨AI训练数据采集的重要性,分析数据采集面临的挑战与机遇,并介绍如何通过Pangolin Scrape API来革新数据采集技术,提升AI训练效率。
AI训练数据采集:Pangolin Scrape API如何助力人工智能学习 Read More »

了解 Pangolin Scrape API——亚马逊网页抓取API的变革性工具,如何以98%以上的成功率捕捉SP广告,实现按指定邮政编码实时数据抓取,揭秘为何它是你所需的数据解决方案。
亚马逊网页抓取API解析:电商数据抓取的现状与解决方案! Read More »

探索亚马逊网络数据抓取的合规性与最佳实践,了解如何在不触犯法规的前提下高效收集情报。本文深入分析了合规重要性、技术团队的作用、合规审查的洞察及构建通用框架的方法,并展示了如 Pangolin 的 Scrape API 如何引领智能化且合规的数据采集新时代。
亚马逊网络数据抓取的合规和最佳实践:Pangolin引领的智能数据获取之道。 Read More »
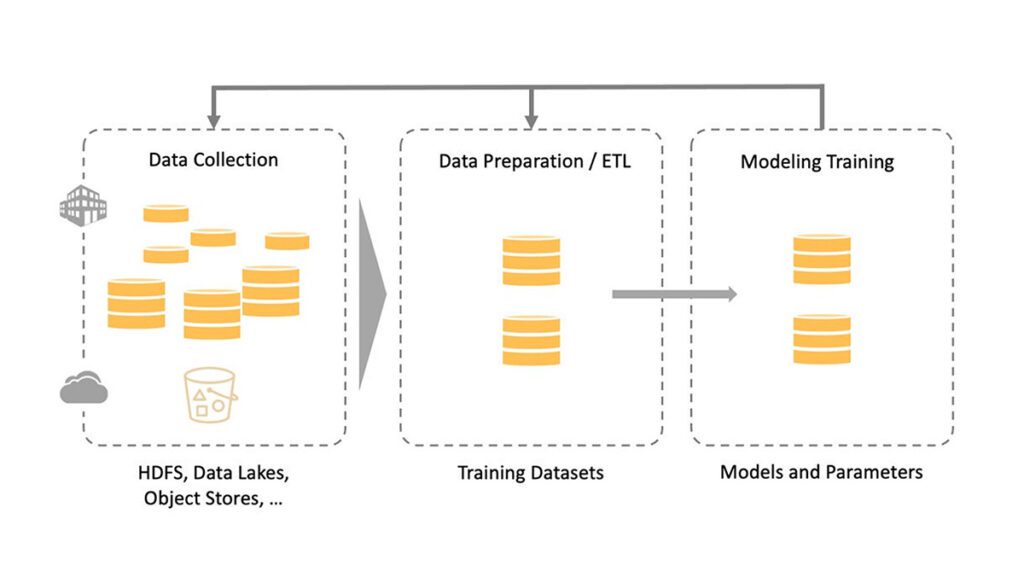
探索AI训练数据抓取的高效策略与前沿工具,揭秘如何合法合规地收集网络信息以优化人工智能模型学习。了解智能抓取助手等软件如何助力非技术人员轻松获取关键词相关的高质量数据,提升AI训练效果,同时讨论数据抓取的法律边界与最新技术进展。
AI时代的数据富矿:垂直领域数据挖掘的挑战与机遇 Read More »

掌握亚马逊关键词抓取秘诀,利用高效数据抓取技术实现销量飞跃。本文深度解析关键词抓取的重要性,传统方法的局限性,介绍自动抓取工具的革新,并重点推介Pangolin Scrape API如何在三分钟内提供实时数据,助力卖家精准定位关键词、优化广告投放,实现从新手到顶级卖家的蜕变。探索智能数据抓取如何塑造电商竞争新优势。
解锁亚马逊关键词采集工具:如何高效采集数据以驱动销售增长? Read More »
