
亚马逊网络数据抓取的合规和最佳实践:Pangolin引领的智能数据获取之道。
探索亚马逊网络数据抓取的合规性与最佳实践,了解如何在不触犯法规的前提下高效收集情报。本文深入分析了合规重要性、技术团队的作用、合规审查的洞察及构建通用框架的方法,并展示了如 Pangolin 的 Scrape API 如何引领智能化且合规的数据采集新时代。
亚马逊网络数据抓取的合规和最佳实践:Pangolin引领的智能数据获取之道。 Read More »
探索亚马逊网络数据抓取的合规性与最佳实践,了解如何在不触犯法规的前提下高效收集情报。本文深入分析了合规重要性、技术团队的作用、合规审查的洞察及构建通用框架的方法,并展示了如 Pangolin 的 Scrape API 如何引领智能化且合规的数据采集新时代。
亚马逊网络数据抓取的合规和最佳实践:Pangolin引领的智能数据获取之道。 Read More »
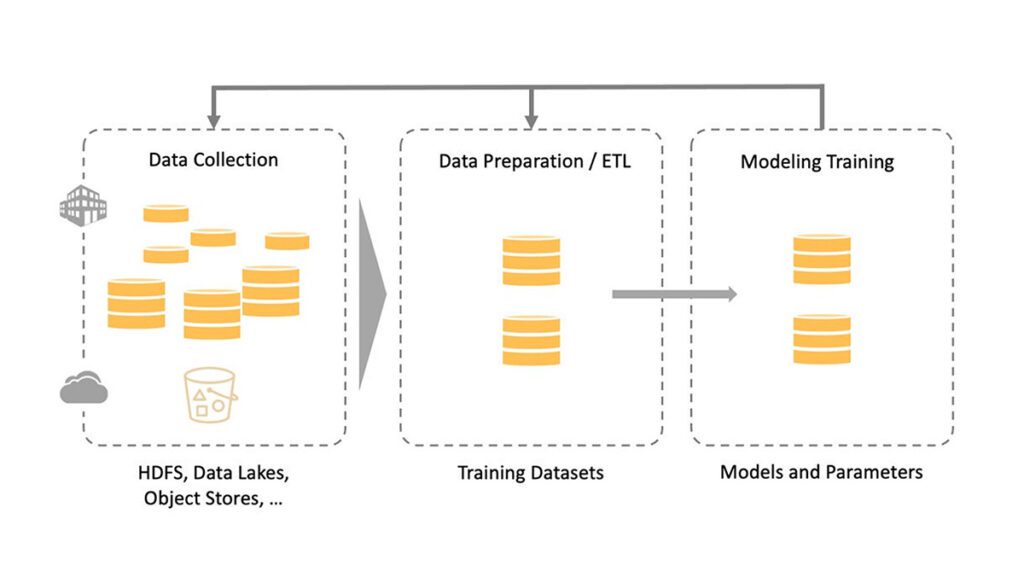
探索AI训练数据抓取的高效策略与前沿工具,揭秘如何合法合规地收集网络信息以优化人工智能模型学习。了解智能抓取助手等软件如何助力非技术人员轻松获取关键词相关的高质量数据,提升AI训练效果,同时讨论数据抓取的法律边界与最新技术进展。
AI时代的数据富矿:垂直领域数据挖掘的挑战与机遇 Read More »

掌握亚马逊关键词抓取秘诀,利用高效数据抓取技术实现销量飞跃。本文深度解析关键词抓取的重要性,传统方法的局限性,介绍自动抓取工具的革新,并重点推介Pangolin Scrape API如何在三分钟内提供实时数据,助力卖家精准定位关键词、优化广告投放,实现从新手到顶级卖家的蜕变。探索智能数据抓取如何塑造电商竞争新优势。
解锁亚马逊关键词采集工具:如何高效采集数据以驱动销售增长? Read More »

探索高效亚马逊ASIN抓取工具,解锁电商数据分析新境界。本文汇总了市面上领先的ASIN采集软件,重点介绍了Pangolin Scrape API等智能工具的特点与优势,包括制定助邮区数据抓取等先进功能。您精准把握市场动态,优化商品策略。
亚马逊ASIN抓取工具:解锁电商数据宝藏的钥匙。 Read More »

引言:AI时代的数据脉动 我们生活在一个数据爆炸的时代,人工智能(AI)正逐渐成为我们生活的核心。从自动驾驶汽
驾驭数据洪流:AI模型训练的数据采集挑战与解决方案 Read More »

本文深度解读了2024年公共网络数据报告,强调了公共网络数据对全球经济的重要性,以及各行业如何利用公共网络数据进行创新和竞争优势。文章还详细介绍了Pangolin Scrape API的功能特点及优势,为读者提供了专业的公共网络数据抓取解决方案。
2024年公共网络数据报告深度解读:数据驱动的商业创新之路 Read More »

在电商行业,数据采集工程师面临着大量数据、快速更新、复杂格式等挑战。本文深入探讨电商数据采集的现状与难题,并介绍Pangolin Scrape API和Pangolin采集器这两种高效的数据抓取工具,旨在帮助工程师们提升数据采集效率,确保数据质量,助力电商企业洞察市场动态,优化营销策略。
电商行业数据采集中需要面对哪些挑战? Read More »

深入探索专为亚马逊卖家量身定制的数据采集解决方案,这套方案旨在全方位、精准地抓取平台上的产品详情、销售趋势、竞品分析等多元关键数据。通过运用先进的数据抓取技术,商家能实时获取到关乎业绩提升与市场竞争力的核心情报,从而实现对自身运营的精细化管理与动态调整。无论是优化商品列表、制定定价策略,还是洞悉消费者行为、快速响应市场变化,该方案都能提供强大数据支撑,助力商家在激烈的电商竞争中立于不败之地,持续提升运营效益,驱动业务增长
解锁电商潜力:高效亚马逊数据采集解决方案助力智慧决策! Read More »

Web爬虫采集亚马逊数据:深度解析与实战指南。掌握高效抓取亚马逊平台各类商品信息、用户评价、销售趋势等关键数据的核心技术,了解法规合规边界,规避反爬机制,运用Python、Scrapy等工具构建定制化爬虫系统。附带真实案例分析与最佳实践分享,助力企业与研究人员精准洞察市场动态,驱动数据驱动型决策,提升竞争力。全程涵盖数据清洗、存储、分析与可视化环节,打造完整数据采集到价值提炼的闭环之旅。
Web爬虫采集亚马逊数据实战!从零开始理解亚马逊数据采集。 Read More »

本文深入探讨了数据采集领域的创新技术,包括自动化数据采集、物联网技术、边缘计算技术和区块链技术等。这些创新技术正在推动数据采集的发展,提高了数据的准确性、实时性和安全性,同时在商业、医疗健康、城市管理等领域展现出了广阔的应用前景。