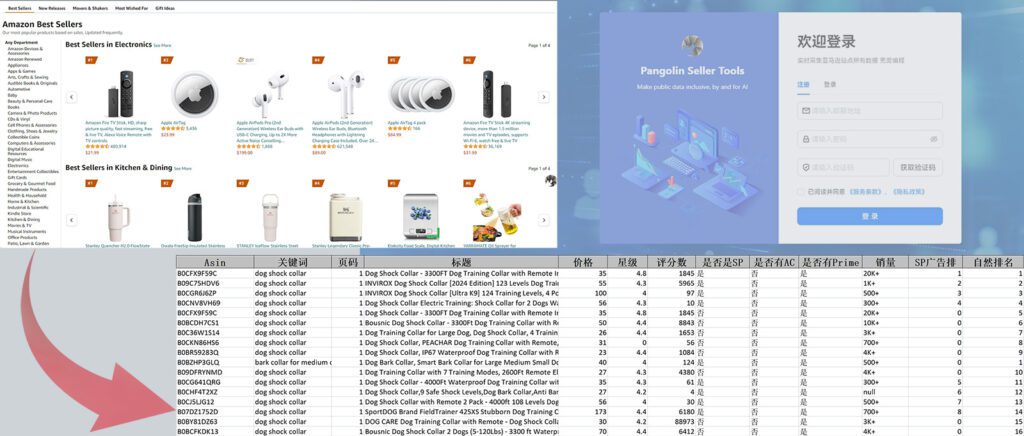
引言
亚马逊热卖榜数据的重要性和应用场景
亚马逊热卖榜的数据代表了市场上最受欢迎的商品。对于电商分析和市场研究人员来说,这些数据提供了宝贵的见解。例如,通过分析热卖榜数据,可以了解当前的市场趋势、消费者偏好以及热门商品的特性。
数据采集在电商分析和市场研究中的作用
数据采集在电商分析和市场研究中具有重要意义。通过获取和分析数据,企业可以监控竞争对手的动向、制定产品定位和市场策略,以及优化库存管理和营销策略。
使用Python进行数据采集的动机和目标
Python以其强大的库和简单的语法成为数据采集的首选语言。使用Python,我们可以自动化地获取亚马逊热卖榜的数据,进行实时分析和决策支持。
一、为什么要采集亚马逊热卖榜数据
市场趋势分析
通过采集亚马逊热卖榜数据,可以识别市场中的热门商品,了解当前消费者的需求和偏好。这对于企业调整产品策略和预测市场走向非常有帮助。
竞争对手监控
监控竞争对手的热卖商品和销售策略,可以帮助企业找到市场中的机会和威胁,及时调整自身的营销和销售策略。
产品定位和市场策略制定
通过分析热卖商品的数据,企业可以更好地定位自身产品,制定更有针对性的市场策略,提高市场竞争力。
二、采集亚马逊热卖榜数据的挑战
动态内容加载的技术难题
亚马逊热卖榜页面通常采用动态加载技术,数据并非直接嵌入在HTML中,而是通过JavaScript动态加载,这给数据采集带来了挑战。
反爬虫机制的规避
亚马逊网站具有复杂的反爬虫机制,包括IP封禁、CAPTCHA验证等。有效规避这些机制是数据采集过程中需要解决的重要问题。
数据的实时性和准确性保证
为了确保数据的实时性和准确性,爬虫需要处理频繁的数据更新和变化,同时保证数据抓取的稳定性和完整性。
三、环境准备和工具选择
Python环境搭建
首先,需要搭建Python环境。推荐使用Anaconda来管理Python环境和依赖库,便于后续开发和维护。
必要库的安装:Selenium、Webdriver Manager、pandas等
在搭建好Python环境后,需要安装必要的库:
pip install selenium webdriver-manager pandas
- Selenium:用于自动化浏览器操作
- Webdriver Manager:简化浏览器驱动的管理
- pandas:用于数据处理和分析
开发工具的选择和配置
推荐使用VSCode或PyCharm作为开发工具,这些工具提供了强大的代码编辑和调试功能,有助于提高开发效率。
四、爬虫基础:了解亚马逊网站结构
亚马逊热卖榜页面分析
首先,需要分析亚马逊热卖榜页面的结构,了解数据的加载方式和页面元素的位置。这可以通过浏览器的开发者工具(F12)来进行。
页面元素的检查和定位方法
通过开发者工具,可以检查页面中的HTML结构,找到包含商品信息的元素。这些元素通常以特定的标签和属性标识,例如商品名称可能位于<span>标签中,价格可能位于<span class="price">中。
五、编写爬虫脚本
初始化Webdriver
首先,初始化Webdriver:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
这段代码使用Webdriver Manager自动下载并配置Chrome驱动。
配置和启动浏览器
可以配置浏览器选项,例如无头模式(Headless Mode),以提高抓取效率:
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
导航至目标页面
使用Selenium导航至亚马逊热卖榜页面:
url = 'https://www.amazon.com/Best-Sellers/zgbs'
driver.get(url)
使用Selenium打开亚马逊热卖榜页面
确保页面完全加载后,再进行数据抓取:
import time
time.sleep(5) # 等待页面加载完成
解析和定位元素
使用Xpath或CSS选择器定位商品数据:
products = driver.find_elements_by_xpath('//div[@class="zg-item-immersion"]')
六、数据抓取实战
处理动态加载内容
对于动态加载的内容,可以使用Selenium的等待机制:
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
products = wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="zg-item-immersion"]')))
抓取商品信息
遍历商品列表,提取名称、价格、评分、销量等信息:
data = []
for product in products:
name = product.find_element_by_xpath('.//span[@class="p13n-sc-truncated"]').text
price = product.find_element_by_xpath('.//span[@class="p13n-sc-price"]').text
rating = product.find_element_by_xpath('.//span[@class="a-icon-alt"]').text
data.append({'name': name, 'price': price, 'rating': rating})
处理分页和无限滚动
对于分页和无限滚动,需要编写自动翻页和滚动的代码:
while True:
try:
next_button = driver.find_element_by_xpath('//li[@class="a-last"]/a')
next_button.click()
time.sleep(5) # 等待新页面加载
products = driver.find_elements_by_xpath('//div[@class="zg-item-immersion"]')
except:
break # 没有更多页面,退出循环
七、数据存储与处理
使用pandas处理和存储抓取的数据
将抓取的数据转换为DataFrame并保存为CSV文件:
import pandas as pd
df = pd.DataFrame(data)
df.to_csv('amazon_best_sellers.csv', index=False)
数据清洗和格式化
对数据进行清洗和格式化,以便后续分析:
df['price'] = df['price'].str.replace('$', '').astype(float)
df['rating'] = df['rating'].str.extract(r'(\d+\.\d+)').astype(float)
八、注意事项和常见问题
遵守robots.txt协议
在爬取数据前,检查目标网站的robots.txt文件,确保爬虫行为符合网站的规定。
模拟正常用户行为避免被检测
通过增加随机延迟、切换User-Agent等方式模拟正常用户行为,降低被检测的风险:
import random
time.sleep(random.uniform(2, 5)) # 随机延迟
处理异常和错误
在爬虫脚本中加入异常处理机制,提高脚本的健壮性:
try:
# 爬虫代码
except Exception as e:
print(f'Error: {e}')
driver.quit()
九、案例分析
通过具体案例演示爬虫的部署和运行
下面通过具体案例展示完整的爬虫脚本,并运行测试,验证其功能和性能。
完整爬虫脚本
import time
import random
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
# 初始化webdriver
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
# 导航至亚马逊热卖榜页面
url = 'https://www.amazon.com/Best-Sellers/zgbs'
driver.get(url)
time.sleep(5) # 等待页面加载完成
# 抓取数据
data = []
while True:
wait = WebDriverWait(driver, 10)
products = wait.until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="zg-item-immersion"]')))
for product in products:
try:
name = product.find_element_by_xpath('.//span[@class="p13n-sc-truncated"]').text
except:
name = None
try:
price = product.find_element_by_xpath('.//span[@class="p13n-sc-price"]').text
except:
price = None
try:
rating = product.find_element_by_xpath('.//span[@class="a-icon-alt"]').text
except:
rating = None
data.append({'name': name, 'price': price, 'rating': rating})
try:
next_button = driver.find_element_by_xpath('//li[@class="a-last"]/a')
next_button.click()
time.sleep(random.uniform(2, 5)) # 随机延迟
except:
break # 没有更多页面,退出循环
# 保存数据
df = pd.DataFrame(data)
df.to_csv('amazon_best_sellers.csv', index=False)
# 清理数据
df['price'] = df['price'].str.replace('$', '').astype(float)
df['rating'] = df['rating'].str.extract(r'(\d+\.\d+)').astype(float)
分析案例中的关键代码和实现逻辑
- 初始化Webdriver和配置浏览器:这部分代码初始化Webdriver并配置无头模式,避免浏览器界面弹出影响性能。
- 导航至目标页面并等待加载:通过
driver.get(url)导航到亚马逊热卖榜页面,并使用time.sleep等待页面完全加载。 - 抓取数据:使用
while True循环抓取所有页面的数据,处理每个商品的信息并保存到data列表中。 - 处理分页和随机延迟:通过定位并点击“下一页”按钮实现分页抓取,并使用
random.uniform增加随机延迟,模拟正常用户行为。 - 保存和清理数据:将抓取的数据保存为CSV文件,并使用pandas进行数据清理和格式化,便于后续分析。
十、采集亚马逊数据的现状与难点
当前数据采集的普遍做法和效果
目前,数据采集普遍使用的工具和方法包括Selenium、Scrapy、BeautifulSoup等。这些工具各有优劣,Selenium适用于动态加载页面的抓取,而Scrapy和BeautifulSoup适用于静态页面的数据提取。
面临的主要难点和挑战
在数据采集过程中,主要面临以下几个难点和挑战:
- 反爬虫机制:许多网站使用复杂的反爬虫机制,如IP封禁、CAPTCHA验证等,需要通过代理池、模拟用户行为等方式规避。
- 数据格式复杂性:一些页面的数据结构复杂且多变,需要编写灵活的解析代码。
- 实时性要求:为了确保数据的实时性,爬虫需要频繁运行并及时更新抓取的数据。
十一、更好的选择:Pangolin Scrape API
Pangolin Scrape API的产品特点和优势
Pangolin Scrape API是一种高效的数据采集解决方案,提供了无需维护爬虫、代理和绕过验证码的能力,使数据采集更加便捷和稳定。
无需维护爬虫、代理、绕过验证码等
通过Pangolin Scrape API,用户无需手动维护爬虫脚本和代理池,也无需处理复杂的验证码,极大简化了数据采集的工作。
实时数据获取和指定邮编采集的能力
Pangolin Scrape API提供实时数据获取和指定邮编采集的功能,进一步提高数据的精准性和实用性。例如,可以按地区获取特定邮编的商品数据,进行更精细化的市场分析。
十二、总结
总结Python爬虫的实现步骤和关键点
本文详细介绍了使用Python爬虫采集亚马逊热卖榜数据的步骤和关键点,包括环境准备、编写爬虫脚本、处理动态加载内容、抓取商品信息、数据存储与处理等。
Pangolin Scrape API作为替代方案的优势
虽然Python爬虫在数据采集中非常强大,但面对复杂的反爬虫机制和实时性要求,Pangolin Scrape API提供了一种更高效、更稳定的替代方案,简化了数据采集的工作流程。
进一步学习和探索的资源
进一步学习和探索的资源,包括Python爬虫教程、数据分析工具:


